Getting started with Kubernetes Cloud Agnostic journey ☸️ ☁️
Day 0: Drafting idea... ✍️ 💡

The idea of building up a no-vender-lock-in, portable and service-agnostic infrastructure is quite appealing to many DevOps engineers and I’m no exception. I’ve been working with kubernetes clusters that hosted on cloud providers (AWS, Azure, GCP) or installed on the on-premise infrastructure. However my experience with deploying and operating kubernetes clusters on multiple clouds and environments is quite limited.
Recently, I’ve the chance to join a project of a startup company that requires me to setup and operate an infrastructure that described as “cloud agnostic” and “portable”. As a result, I’ve decided to write this series to note down the knowledge and experiences that I’ve undergone when taking on this journey.
Context
Let’s imagine this scenario: A startup company which has successfully claimed the AWS credit from the startup program. After a period of time using above AWS credit the company has received Azure credit from the Microsoft for startups program and they want to migrate the kubernetes infrastructure on AWS to Azure. Maybe in the future this startup will successfully request startup GCP credit and the migrate requirement will emerge again. The goal is to utilize credits provided from cloud providers in order to reduce infrastructure cost as much as possible.
We can fast forward to the time when this startup company has grown to the point that they need to scale their infrastructure on multi-cloud environment in order to serve users from all over the world. They may also have the requisite for data privacy so that they will have the demand to provision an on-premise infrastructure.
From above scenario we can draw the requirement for this startup infrastructure is to build up a “cloud agnostic” one. With a cloud agnostic infrastructure we can seamlessly migrate kubernetes clusters from one cloud provider to another one, these kubernetes clusters can be run on any cloud providers and can prevent company from falling into “vender lock-in” hole. With the “cloud agnostic” mindset when deploying the kubernetes infrastructure we can help the startup achieve the multi-cloud or hybrid environment with minimal operational effort.
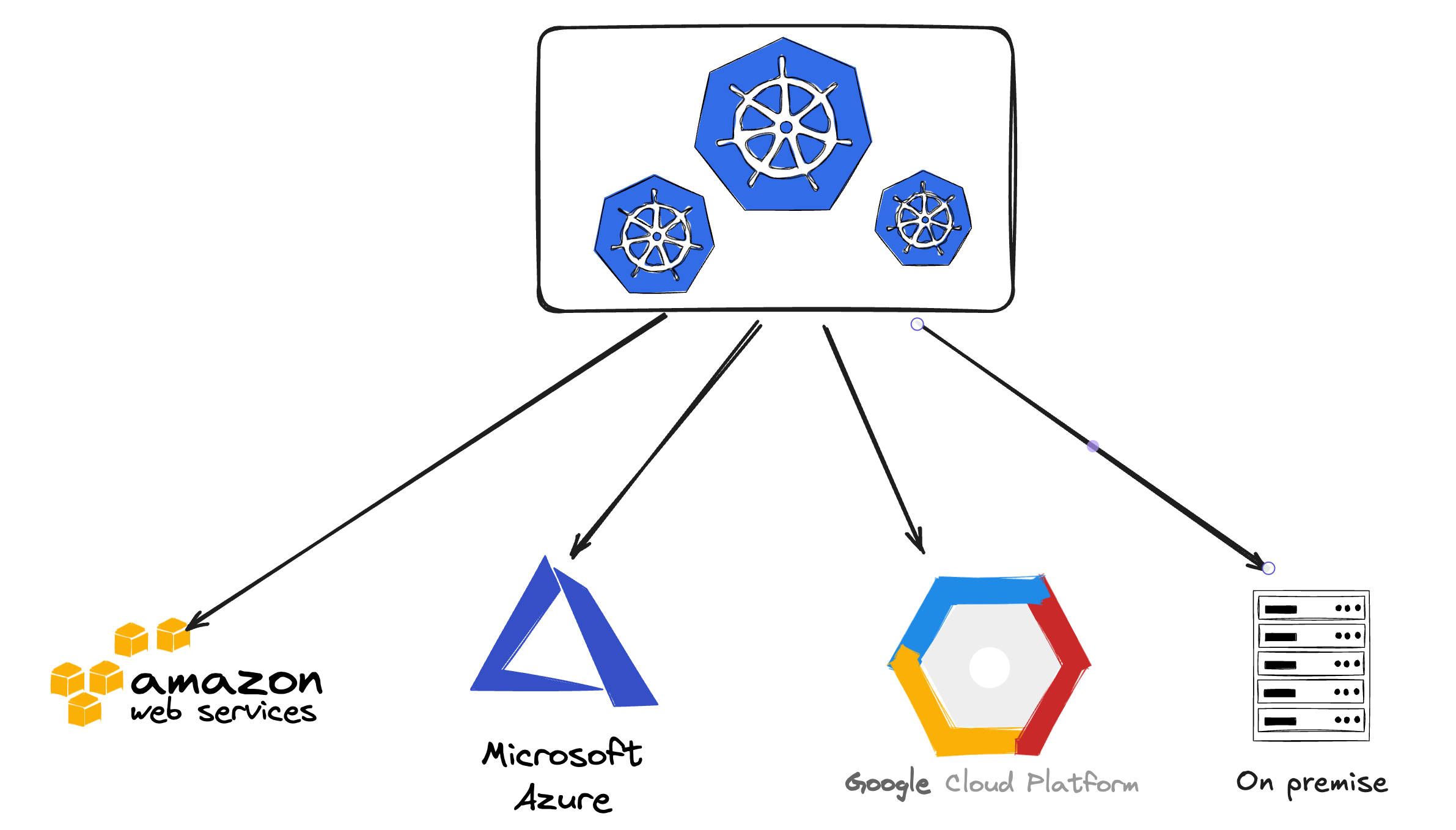
Of course this “cloud agnostic” approach has it own pros and cons, I will try to provide both of them in order to have the most subjective viewpoint when we gradually moving through each module of the series. Since in the end there is no such thing as the most optimal solution, it is always about the tradeoffs among the solutions.
Checklist
Since this is just the Day 0 of the journey so that I’m still quite vague about what to do and where to start so below things are just my draft for what I will (maybe) do in this series:
Bootstrap “cloud agnostic” kubernetes clusters
Communication among clusters
Deploy microservices on multi-clusters
GitOps for multi-clusters deployment
CI/CD for multi-clusters
Monitoring, logging and tracing on multi-clusters
Backup and recover kubenetes clusters
Handling stateful application in “cloud agnostic” infrastructure
Scheduling and bin-packing problems on multi-clusters
… (I will update if any interesting ideas come up)
Since the infrastructure is “cloud agnostic” so I will try to utilize the open sources as mush as possible.
Let’s get started 🚢 I hope my upcoming articles will be helpful to you.
Link to next days in the journey: